《后端技术(服务器)》
框架
基础工具库
Apache commons
- Commons IO
FileAlterationMonitor和FileAlterationObserver(Alyx 曾发现这里每隔 10 秒会涨 10M 内存,待研究)
- Commons Lang3 等
Google Guava
Google Guava 是 Google 公司内部 Java 开发工具库的开源版本。Google 内部的很多 Java 项目都在使用它。它提供了一些 JDK 没有提供的功能,以及对 JDK 已有功能的增强功能。
- 主要包括了:
- 集合(Collections)
- 缓存(Caching)
- 原生类型支持(Primitives Support)
- 并发库(Concurrency Libraries)
- 通用注解(Common Annotation)
- 字符串处理(Strings Processing)
- 数学计算(Math)
- I/O 事件
- 总线(EventBus)
一些有用的小工具:
BloomFilter布隆过滤器的实现- Ordering排序器
Json
Spring
Spring
最好能抽空看看源码,最起码 bean 的生命周期,如何解决循环依赖,父子容器,还有 boot 的启动流程,事务实现原理,动态代理原理等,你知道越多越好。
-
IOC 依赖注入,控制反转
循环依赖及三级缓存
弄清楚:
三级缓存是分别是什么,分别是什么时候起作用?
为何需要三级缓存,二级缓存不行吗?
Spring 对 groovy 的生成的 bean 为何解决不了循环依赖?
这里主要是:
bean 生成的时机是 postProcessBeforeInstantiation,没有走到 doCreateBean,而 addSingletonFactory 是在 doCreateBean 调用的
protected void addSingletonFactory(String beanName, ObjectFactory singletonFactory) { Assert.notNull(singletonFactory, "Singleton factory must not be null"); synchronized (this.singletonObjects) { if (!this.singletonObjects.containsKey(beanName)) { this.singletonFactories.put(beanName, singletonFactory); this.earlySingletonObjects.remove(beanName); this.registeredSingletons.add(beanName); } } }bean 是由 ScriptFactoryPostProcessor#scriptBeanFactory 生成的,这个 scriptBeanFactory 是一个全新的,然后 copyConfigurationFrom 了一次 parent 的属性
@Configuration
@Configuration注解的类为什么被CGLIB增强?
@Configuration这注解为什么可以不加?加了和不加的区别,底层为什么使用cglib - 简书 (jianshu.com)
Spring AOP
AOP 原理,ProxyFactory
AOP 中 Pointcut,Advice 和 Advisor 三个概念 还有 Advised
Advised
在 Spring 中创建了 AOP 代理之后,就能够使用 org.springframework.aop.framework.Advised 接口对它们进行管理。 任何 AOP 代理都能够被转型为这个接口,不论它实现了哪些其它接口
Advisor
类似使用 Aspect 的@Aspect 注解的类
Advice
@Before、@After、@AfterReturning、@AfterThrowing、@Around
Pointcut
@Pointcut
Spring tx
<tx:annotation-driven/>的解析过程@Transactional代理过程,用的什么代理,怎么代理
这里有一点需要注意的地方,由于 SpringAOP 的原因,@Transactional 注解只能用到 public 方法上,如果用到 private 方法上,将会被忽略,这也是面试经常问的考点之一。
组件整合
Spring Webflux (reactive web 框架,与前端 Flux 架构名字相同)
命令式编程 VS 响应式编程
Spring Data
与其他构架的整合
SpringBoot
- SpringBoot 自动配置机制
- SpringBoot 启动过程
- SpringBootStarter 依赖
简易教程
SpringCloud
核心子项目:
- Spring Cloud Netflix:核心组件,可以对多个 Netflix OSS 开源套件进行整合,包括以下几个组件:
- Eureka:服务治理组件,包含服务注册与发现
- Hystrix:容错管理组件,实现了熔断器
- Ribbon:客户端负载均衡的服务调用组件
- Feign:基于 Ribbon 和 Hystrix 的声明式服务调用组件
- Zuul:网关组件,提供智能路由、访问过滤等功能
- Archaius:外部化配置组件
- Spring Cloud Config:配置管理工具,实现应用配置的外部化存储,支持客户端配置信息刷新、加密/解密配置内容等。
- Spring Cloud Bus:事件、消息总线,用于传播集群中的状态变化或事件,以及触发后续的处理
- Spring Cloud Security:基于 spring security 的安全工具包,为我们的应用程序添加安全控制
- Spring Cloud Consul:封装了 Consul 操作,Consul 是一个服务发现与配置工具(与 Eureka 作用类似),与 Docker 容器可以无缝集成
简易教程:
Spring Cloud 微服务架构学习笔记与示例 - EdisonZhou - 博客园 (cnblogs.com)
ASM 神器
spring-core 自带有 asm,org.ow2.asm 也是一个轻量级的 jar
还有 byte buddy 库,javassist 库
JAX-RS
全称:Java API for RESTful Web Services,是一套用 java 实现 REST 服务的规范,提供了一些标注将一个资源类,一个 POJOJava 类,封装为 Web 资源。
包括:
- @Path,标注资源类或方法的相对路径
- @GET,@PUT,@POST,@DELETE,标注方法是用的 HTTP 请求的类型
- @Produces,标注返回的 MIME 媒体类型
- @Consumes,标注可接受请求的MIME 媒体类型
- @PathParam,@QueryParam,@HeaderParam,@CookieParam,@MatrixParam,@FormParam,分别标注方法的参数来自于 HTTP 请求的不同位置,例如@PathParam 来自于 URL 的路径,@QueryParam 来自于 URL 的查询参数,@HeaderParam 来自于 HTTP 请求的头信息,@CookieParam 来自于 HTTP 请求的 Cookie
Eureka的ApplicationResource有用到
缓存
Guava 的缓存
Guava Cache 说简单点就是一个支持LRU的 ConcurrentHashMap
Caffeine 来自未来的缓存
Caffeine 是基于 JAVA 1.8 Version 的高性能缓存库。Caffeine 提供的内存缓存使用参考 Google guava 的 API。Caffeine 是基于 Google Guava Cache 设计经验上改进的成果。
日志
区分
commons-logging,slf4j,log4j,logbackJava日志,需要知道的几件事(commons-logging,log4j,slf4j,logback)_kobejayandy的专栏-CSDN博客
- 了解
jcl-over-slf4j,jul-to-slf4j这些 jar 的作用 - 了解
log4j和log4j2的区别,lmax disruptor应用场景
- 了解
log4j
Flume日志采集系统,一般用于日志聚合
ORM 库
hibernate
查询:HQL 查询,QBC 查询,SQL 查询
级联查询:一对一,一对多(多对一),多对多;懒加载,1+n 问题
其他:
session.get(): 非懒加载方法
session.load(): 默认就是是懒加载
抓取策略(fetch)和 懒加载(lazy)
mybatis
Netty
Netty 的线程模型
通过Reactor 模型基于多路复用器接收并处理用户请求,内部实现了两个线程池,boss 线程池和 work 线程池,其中 boss 线程池的线程负责处理请求的 accept 事件,当接收到 accept 事件的请求时,把对应的 socket 封装到一个 NioSocketChannel 中,并交给 work 线程池,其中 work 线程池负责请求的 read 和 write 事件
NioEventLoop 设计原理
定时任务的原理
netty 对象池使用与回收
时间轮算法
hashWheel 定时器和 Quartz 的区别:
1)Quartz 将定时任务分为任务和触发器,而 hashWheel 只有任务的概念2)Quartz 通过一个 TreeSet 对所有的触发器进行管理,而 hashWheel 通过一个 hash 轮来对所有的任务进行管理
3)Quartz 能够非常方便的删除定时任务,而 netty 的 hashWheel 暂时没有删除任务的接口(除非自己实现一个 hashWheel 定时器)
4)Quartz 有一个专门的调度线程对任务进行管理,任务执行有另外专门的线程池,而 hashWheel 用一个线程实现对任务的管理和任务的执行。
5)Quartz 能够通过序列化,将定时任务保存在数据库,而 hashWheel 不能
总的来说,Quartz 的功能相对强大,而 hashWheel 相对要轻量级一点。
附:
个人认为 netty 对用户来说是异步,但是实际底层 IO 是 IO 多路复用模型,本质上还是一种同步非阻塞(是的,个人认为 IO 多路复用模型还是同步非阻塞,并且真正的 IO 操作都将阻塞应用线程),他只是多了一个 Selector(需要底层操作系统支持),如此一个线程就可以控制大量的通信(相比传统 IO,不管他是不是非阻塞)。
另看 IO#IO 概念,这里也收录了一些理解
面试
Disruptor
Disruptor 是一个无锁、有界的队列框架,它的性能非常高。
背景
并发中的伪共享问题
代码的并发执行大约是两件事:互斥和变化的可见性。
互斥是关于管理某些资源的竞争更新。
变化的可见性是关于控制何时使这些更改对其他线程可见。
设计上的优势
- 内部数据存储使用环形缓冲(Ring Buffer),这样分配支持了CPU 缓存位置预测,GC 的压力更小
- 尽量使用无锁设计,合理使用 CAS
- 优化数据结构(填充缓存行),解决伪共享问题
- 合理位运算(如 2 次方幂求模),合理使用 Unsafe
策略
WaitStrategy可以选择YieldingWaitStrategy(无锁)参考博客
- 解读 Disruptor 系列,这个系列挺好的,他每篇文章后面都有份参考资料,也可以认真看看
扩展
- AtomicXXX.lazySet 这个方法的作用(Sequence#set 相当于 AtomicLong#lazySet)
- Unsafe 类的作用?为什么要用这个类?除了 JDK,在 Netty、Spring、Kafka、Storm 等非常多的流行开源项目中都使用了 Unsafe
原子类型集合库
避免开销很大的装箱/拆箱操作,节省了原始类型装箱消耗的内存
Koloboke
Eclipse Collections
Fastutil
时间库
- joda 对时间的操作
- Quartz 定时任务
RxJava
" a library for composing asynchronous and event-based programs using observable sequences for the Java VM " (一个在 Java VM 上使用可观测的序列来组成异步的、基于事件的程序的库)
工具
- 构建工具
- Maven
- Gradle
- 十分钟理解 Gradle - Bonker - 博客园
- 慕课实战:Gradle3.0 自动化项目构建技术精讲+实战
- Gradle Distributions
版本管理工具
- Git
持续集成部署
Jenkins
单元测试
逆向工程
Web容器
- tomcat
中间件
Zookeeper
场景
ZooKeeper来做:统一配置管理、统一命名服务、分布式锁、集群管理。
使用分布式系统就无法避免对节点管理的问题(需要实时感知节点的状态、对节点进行统一管理等等),而由于这些问题处理起来可能相对麻烦和提高了系统的复杂性,ZooKeeper 作为一个能够通用解决这些问题的中间件就应运而生了。
原理
Dubbo
Dubbo是一款高性能、轻量级的开源Java RPC框架,它提供了三大核心能力:面向接口的远程方法调用,智能容错和负载均衡,以及服务自动注册和发现。
消息队列
主要使用场景:
异步、削峰、解耦
带来问题:
系统复杂性
消息重复消费、消息丢失、消息的顺序消费等等
数据一致性
其他服务失败导致数据不一致?需要分布式事务?
可用性
MQ挂了咋办?
主流:
Kafka 和 RocketMQ
Kafka
场景
想要保证消息(数据)是有序的,怎么做?
Kafka会将数据写到 partition,单个 partition 的写入是有顺序的。如果要保证全局有序,那只能写入一个 partition 中。如果要消费也有序,消费者也只能有一个。
Kafka 性能优化:
- 零拷贝网络和磁盘
- 优秀的网络模型,基于 Java NIO
- 高效的文件数据结构设计
- Parition 并行和可扩展
- 数据批量传输
- 数据压缩
- 顺序读写磁盘
- 无锁轻量级 offset
参考
RocketMQ
TODO
RabbitMQ
了解其 Exchange (交换器),常用的有四种:direct、topic、fanout、headers
MySQL
sharding-jdbc
支持数据分片,分布式事务,数据库治理
连接池
目的:解决建立数据库连接耗费资源和时间很多的问题,提高性能。
自定义数据库连接池要实现 javax.sql.DataSource 接口,一般都叫数据源。
常用的数据源:
DBCP:Apache推出的Database Connection Pool
C3P0:开源的 JDBC 连接池
其他
apache DBUtils
DBUtils简化了JDBC的开发步骤,使得我们可以用更少量的代码实现连接数据库的功能。
TDDL、cobar 等
搜索引擎
Elasticsearch
倒排索引
和 传统关系型数据库 的对比
Relational DB Databases Tables Rows Columns 关系型数据库 数据库 表 行 列 Elasticsearch Indices Types Documents Fields 搜索引擎 索引 类型 文档 域(字段) 使用
Logstash
Kibana
ELK:ELK 技术栈(ElasticSearch, Logstash, Kibana)搭建实时日志分析平台,将日志保存到 Elasticsearch 中,通过 Logstash 进行分析,并使用 Kibana 来展示和查询。
Lucene、Solr
TODO
SOFAStack
项目 · SOFAStack,是一套用于快速构建金融级云原生架构的中间件,也是在金融场景里锤炼出来的最佳实践。
SOFAJRaft
SOFAJRaft 是一个基于 RAFT 一致性算法的生产级高性能 Java 实现,支持 MULTI-RAFT-GROUP,适用于高负载低延迟的场景。
分布式
理论基石
CAP 原理:
C - Consistent ,一致性
A - Availability ,可用性
P - Partition tolerance ,分区容忍性
分布式系统中网络分区不可避免,一致性和可用性水火不容。
Redis的一致性与可用性:
Redis的主从数据是异步同步的,分布式的Redis并不满足一致性要求。
即使在主从网络断开的情况下,主节点依旧可以正常对外提供服务,满足可用性。
但Redis保证最终一致性,从节点会采用多种策略追赶,尽力保持和主节点一致。
主要算法
一致性 Hash
redis 分片
分布式集群中,生成全局唯一的ID
UUID
String uuid = UUID.randomUUID().toString()
虽然可以保证全局唯一,但占用32位太长,而且无序,入库时性能比较差。
为什么无序的UUID会导致入库性能变差呢?
这就涉及到 B+树索引的分裂:关系型数据库的索引大都是B+树的结构,拿ID字段来举例,索引树的每一个节点都存储着若干个ID。如果我们的ID按递增的顺序来插入,比如陆续插入8,9,10,新的ID都只会插入到最后一个节点当中。当最后一个节点满了,会裂变出新的节点。这样的插入是性能比较高的插入,因为这样节点的分裂次数最少,而且充分利用了每一个节点的空间。但是,如果我们的插入完全无序,不但会导致一些中间节点产生分裂,也会白白创造出很多不饱和的节点,这样大大降低了数据库插入的性能。
数据库自增主键
为了提高性能,在分布式系统中可以用DB proxy请求不同的分库,每个分库设置不同的初始值,步长和分库数量相等
这样一来,DB1生成的ID是1,4,7,10,13....,DB2生成的ID是2,5,8,11,14.....
但这样也不是很好。ID的生成对数据库严重依赖,影响性能,一旦数据库挂掉,服务将变得不可用。
SnowFlake
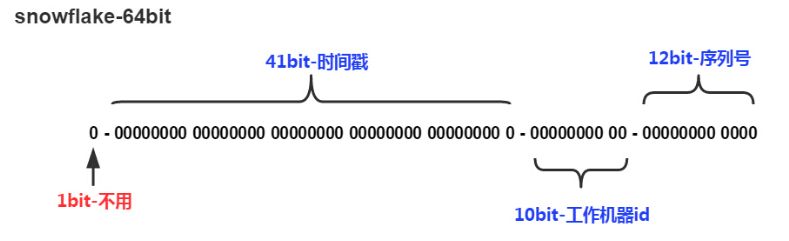
网络通信
RPC
RPC 涉及:通讯,序列化,超时,重发(重复),消息顺序,负载 等等。(个人理解)
- 协议:thrift、gRPC 等等
- JavaRMI
- HSF 阿里巴巴集团内部使用的分布式服务框架 High Speed Framework
Dubbo
一致性
分布式锁
分布式锁一般有三种实现方式:
- 数据库乐观锁;
- 基于 Redis 的分布式锁;(看数据库/Redis篇)
- 基于 ZooKeeper 的分布式锁
分布式事务
和分布式锁的区别
要捋清一些概念:
分布式事务指事务的参与者、支持事务的服务器、资源服务器以及事务管理器分别位于不同的分布式系统的不同节点之上。
简单的说,就是一次大的操作由不同的小操作组成,这些小的操作分布在不同的服务器上,且属于不同的应用,分布式事务需要保证这些小操作要么全部成功,要么全部失败。
本质上来说,分布式事务就是为了保证不同数据库的数据一致性。
共识算法
Paxos、Raft、Zab:
分布式事务一致性的常见解决方案
- 2PC,3PC
- XA
- 消息中间件最终一致性
参考:
Java 分布式事务规范 JTA / XA
JTA 是 Java 的事务管理器规范
XA 是工业标准的 X/Open CAE 规范,可被两阶段提交及回滚的事务资源定义
参考:
- atomikos:4.0 atomikos JTA/XA 全局事务
- xaresource
- 分布式事务
- 分布式事务系列(2.1)分布式事务的概念
分布式 session 一致性
- session 复制,对 web 服务器 (例如 Tomcat) 进行搭建集群
- session 绑定,使用 nginx
ip-hash 策略,无论客户端发送多少次请求都被同一个服务器处理 - 基于 redis 存储,spring 为我们封装好了 spring-session,直接引入依赖即可
高可用
缓存、降级、限流
服务器端如何处理超大量合法请求?
服务器架构层面,做负载均衡,将请求分发给其它服务器处理。
软件服务架构层面,做请求队列,将 1w 个请求放入队列,业务处理完的请求再返回。
代码层面,优化业务处理,把单机请求做到支持 1w 并发。
容量设计
架构演进
- 从All in one 到微服务
- 架构师之路_w3cschool
文件系统
FastDFS
FastDFS 是一个开源的高性能分布式文件系统(DFS)。 它的主要功能包括:文件存储,文件同步和文件访问,以及高容量和负载平衡。主要解决了海量数据存储问题,特别适合以中小文件(建议范围:4KB < file_size <500MB)为载体的在线服务。
用FastDFS一步步搭建文件管理系统 - bojiangzhou - 博客园 (cnblogs.com)
happyfish100/fastdfs-client-java: FastDFS java client SDK (github.com)
大文件传输
大文件上传技术:
在Java中,处理大文件上传的一种常见的方式是使用分片上传。分片上传将大文件切割成一系列的小文件块,然后分别上传这些块。在上传完成后,服务器端会将这些块重新合并成原始文件。
大文件下载技术:
可以使用Java的 RandomAccessFile 类来实现断点续传和并发下载。
将文件分成几块,每块用不同的线程进行下载。
另一种是使用 MappedByteBuffer,MappedByteBuffer是Java提供的基于操作系统虚拟内存映射(MMAP)技术的文件读写API,底层不再通过read、write、seek等系统调用实现文件的读写。
大文件上传时如何做到秒传? | 二哥的Java进阶之路 (javabetter.cn)
Java文件的简单读写、随机读写、NIO读写与使用MappedByteBuffer读写-腾讯云开发者社区-腾讯云 (tencent.com)
防止文件被篡改
信息摘要算法,md5和sha256等
前沿技术
网络协议
RSocket
RSocket是一种二进制的点对点通信协议,是一种新的网络通信第七层协议。旨在用于分布式应用程序中。从这个意义上讲,RSocket是HTTP等其他协议的替代方案。它是一种基于Reactive Streams规范具有异步,背压的双向,多路复用,断线重连,基于消息等特性。它由Facebook,Netifi和Pivotal等工程师开发,提供Java,JavaScript,C ++和Kotlin等实现。
入门使用:
RSocket协议初识-Java中使用(二)_后厂村老司机的博客-CSDN博客
容器化
Docker
大家需要注意,Docker本身并不是容器,它是创建容器的工具,是应用容器引擎。
想要搞懂Docker,其实看它的两句口号就行。
第一句,是“Build, Ship and Run”。也就是,“搭建、发送、运行”,三板斧。
第二句口号就是:“Build once,Run anywhere(搭建一次,到处能用)”。
K8S
就在Docker容器技术被炒得热火朝天之时,大家发现,如果想要将Docker应用于具体的业务实现,是存在困难的——编排、管理和调度等各个方面,都不容易。于是,人们迫切需要一套管理系统,对Docker及容器进行更高级更灵活的管理。
就在这个时候,K8S出现了。
K8S,就是基于容器的集群管理平台,它的全称,是kubernetes。
ServiceMesh
ServiceMesh,也叫服务网格,是一种概念。
一言以蔽之:Service Mesh 是微服务时代的 TCP/IP 协议。
中台
构建中台的目的
中台的目的是构建企业级统一的服务接口,不只是数据,包括技术、业务、组织架构等,其实质是整合企业内的软硬件资源,包括人力资源。传统单体系统,一个系统一套软硬件开发和运维人员,这些系统所采用的厂商、技术、开发语言、技术架构、数据库等可能各不相同。随着信息化系统越来越多,系统间面临着数据共享的要求。所以系统集成技术就应运而生。
什么是中台?为什么需要中台? - 知乎 (zhihu.com)
思想
Reative 编程
Reactive 响应式 (反应式) 编程 是一种新的编程风格,其特点是异步或并发、事件驱动、推送 PUSH 机制以及观察者模式的衍生。
JVM 应用:RxJava、Akka、Actors 模型、Vert.x、Webflux
领域驱动设计
他是综合软件系统分析和设计的面向对象建模方法,如今已经发展为一种针对大型复杂系统的领域建模与分析方法。
将要解决的业务概念和业务规则转换为软件系统中的类型及类型的属性与行为,通过合理运用面向对象的封装、继承、多态等设计要素,降低或隐藏整个系统的业务复杂性,并使得系统具有更好的扩展性,应对纷繁多变的现实业务问题。
——抄录于《高可用可伸缩微服务架构:基于 Dubbo、Spring Cloud 和 Service Mesh》2.1 节
代码评审
基本(规范,模块化,逻辑)
安全(表单校验,防攻击SQL注入,线程安全)
数据库(事务,sql优化)
性能
性能优化
CPU 伪共享问题
问题:二维数组按行和按列遍历效率(Java章节中有说明)
应用:netty 中的 FastThreadLocal 中 InternalThreadLocalMap(Java章节中有说明);lmax disruptor 等
对象池
安全
鉴权
Java 反序列化
log4j
CVE-2019-17571:log4j<=1.2.17反序列化漏洞
CVE-2021-44228:
dubbo
Gadgetinspector
一款针对Java应用程序/库的字节码分析工具,它可以帮助研究人员寻找和分析Java应用程序中的反序列化小工具链(Gadget Chain)
https://github.com/JackOfMostTrades/gadgetinspector
Java 反序列化工具 gadgetinspector 初窥
源码学习
这些框架的源码都值得一看:
- spring
- dubbo
- zookeeper
- tomcat
书单
Spring
- 《Spring 源码深度解析 第二版》《Spring 实战》
- 《Spring Boot 编程思想(核心篇)》
- 《Spring Boot 实战》
- 《Spring 微服务实战》
MySQL
- 《高性能 MySQL》
Netty
- 《Netty 权威指南》
Tomcat
- 《Tomcat 架构解析 (刘光瑞)》
其他
- 《架构探险分布式服务框架 (李业兵)》